Intuition
Inspired by influence functions1, we define influential samples as those vulnerable to MIA. SOFT selectively replaces influential samples, i.e., those are easily memorized and exhibit lower loss values, with their obfuscated counterparts.
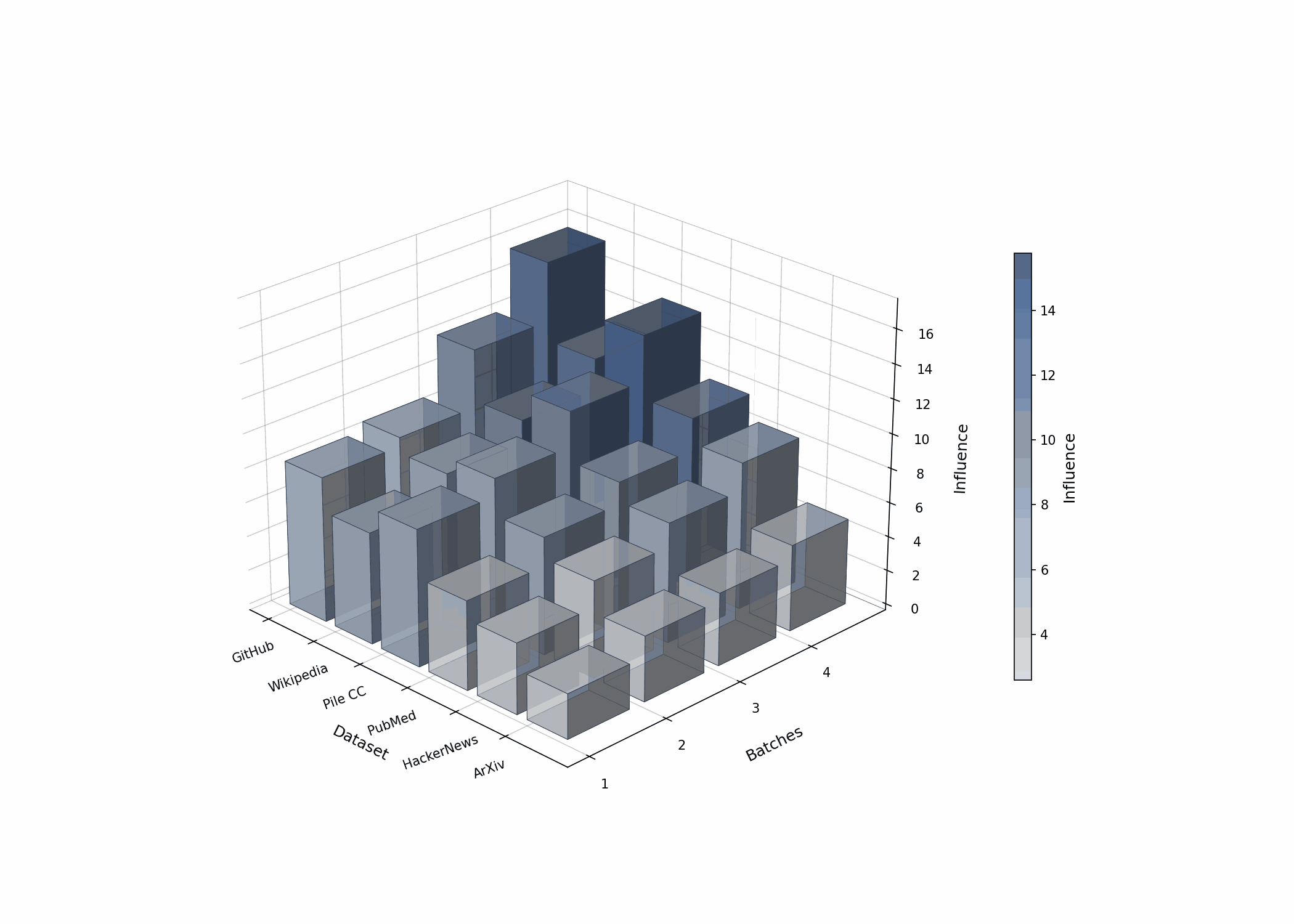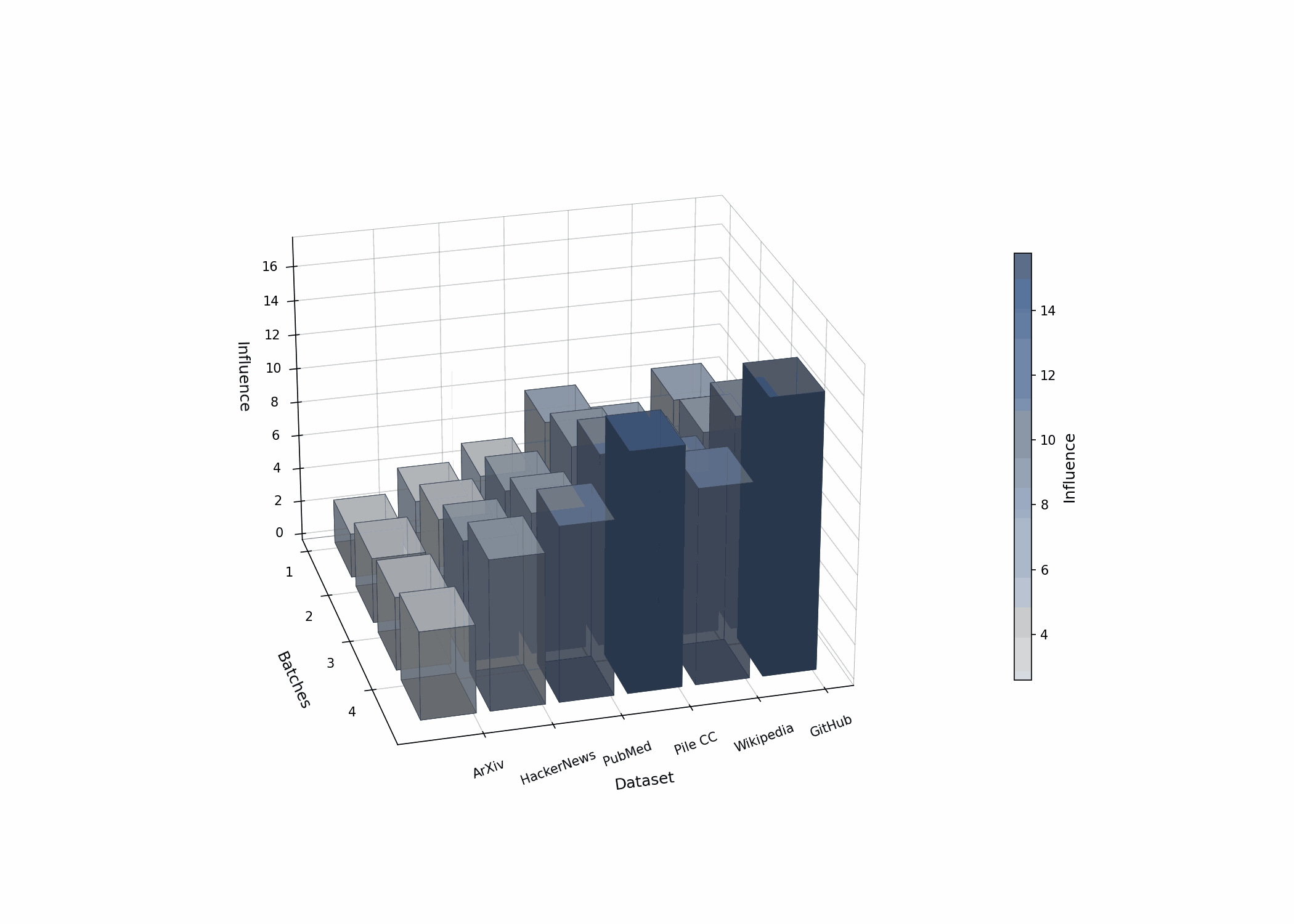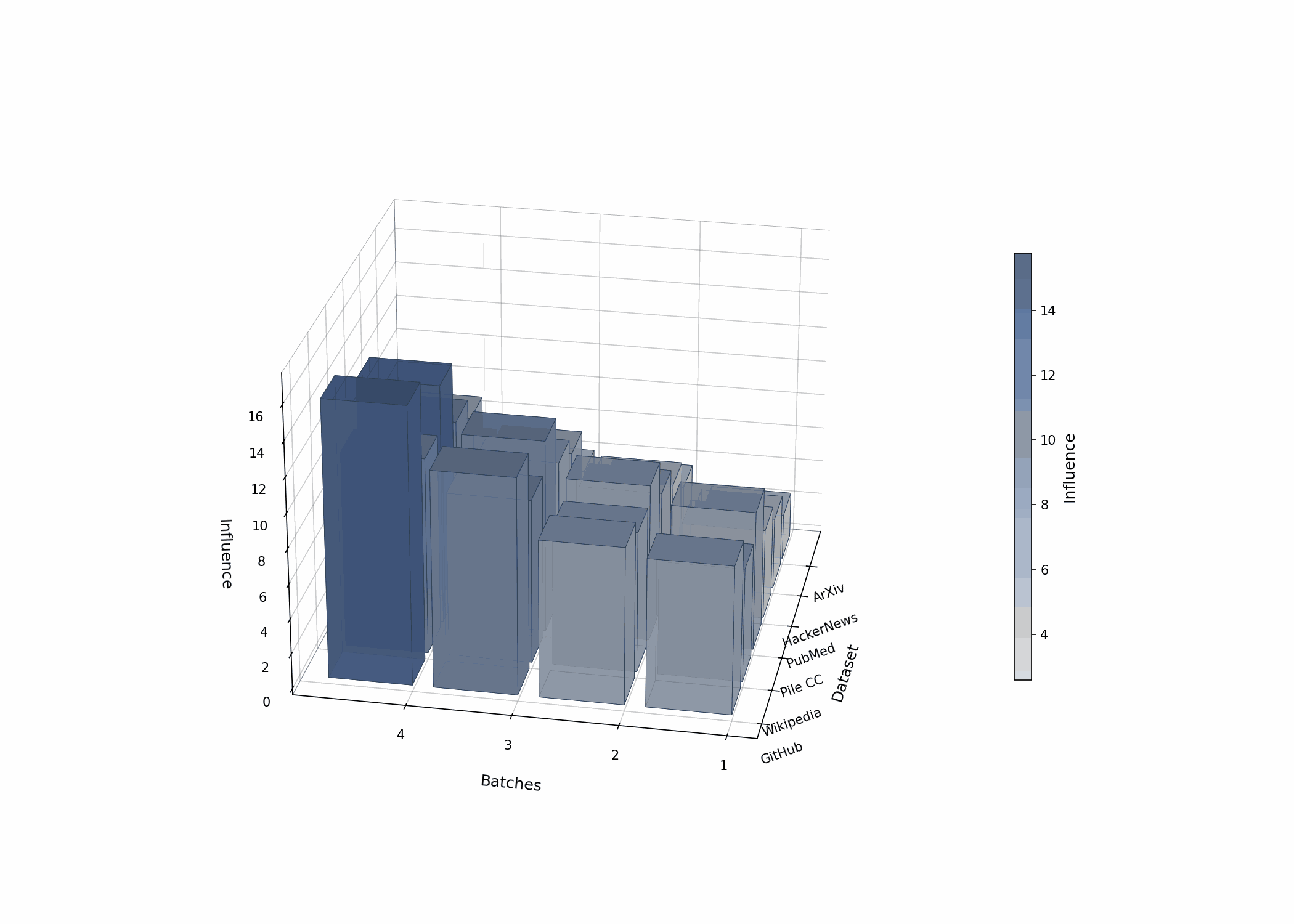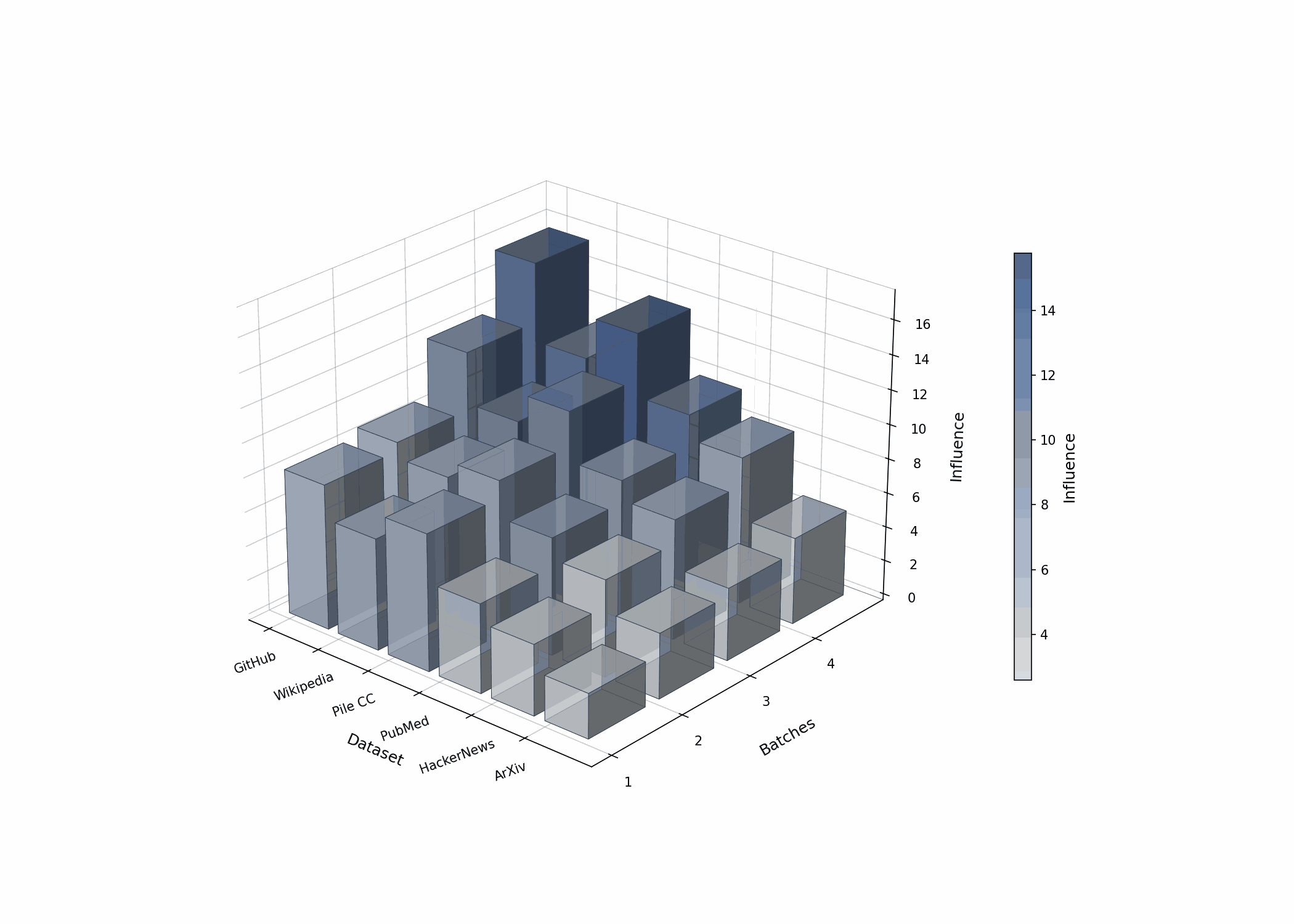
The Calibration Challenge
Existing LLM MIAs mainly differ on how to differentiate uncommon sentences used in training from common sentences not used in training. Many of these methods share similarities on calibration and differ mainly in their use of loss, log-likelihood, perplexity, contrastive ratios, or an extra reference model.
Abstract
Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (Selective data Obfuscation in LLM Fine-Tuning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.

The core idea of SOFT involves substituting influential samples with
semantically equivalent alternatives by a paraphraser during fine-tuning.
Selective Data Obfuscation
Warm-up Fine-tuning
Warm-up helps assess the initial influence level of each sample
Influential Data Selection
SOFT evaluates sample from the fine-tuning dataset and select influential ones
Data Obfuscation
SOFT replaces the selected influential samples with paraphrased versions
Fine-tuning
Combining the obfuscated data with the remaining safe data, SOFT fine-tunes on the updated dataset
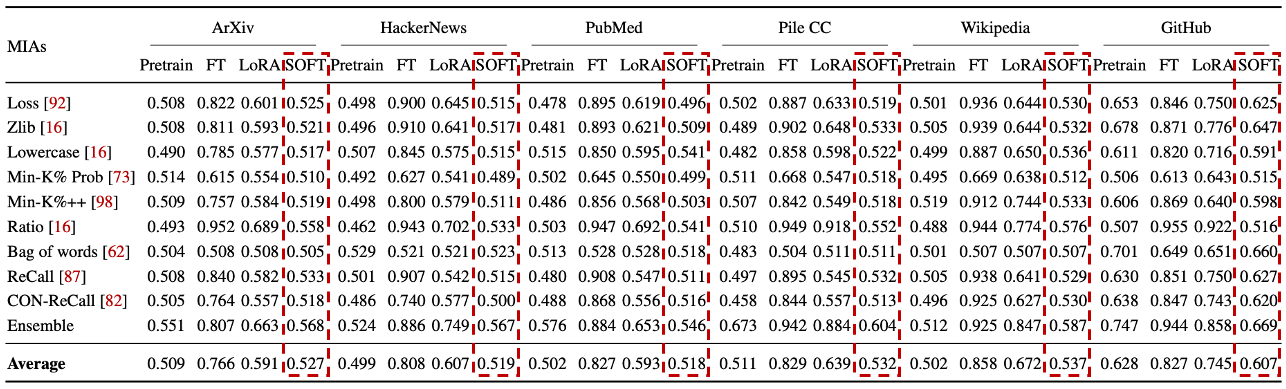
Defense Effectiveness
References
1 Koh, Pang Wei, and Percy Liang. "Understanding black-box predictions via influence functions." International Conference on Machine Learning (ICML), 2017. ↩
BibTeX
@inproceedings{zhang2025soft,
title = {SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks},
author = {Zhang, Kaiyuan and Cheng, Siyuan and Guo, Hanxi and Chen, Yuetian and Su, Zian and An, Shengwei and Du, Yuntao and Fleming, Charles and Kundu, Ashish and Zhang, Xiangyu and Li, Ninghui},
booktitle = {34th USENIX Security Symposium (USENIX Security 25)},
year = {2025},
address = {Seattle, WA},
publisher = {USENIX Association},
month = aug
}